Don’t Let AI Hallucinations Ruin Your Credibility: Use Expert AI Prompts for Consultants
Consultants build their practices on a single, fragile asset: the belief that what they produce is accurate. Not just well-written. Not just strategically framed. Accurate. When a client opens a proposal, reads an industry report, or acts on a strategic recommendation, they’re operating on the assumption that the information inside it reflects reality.
AI hallucinations — outputs that are fluent, confident, and factually wrong — put that assumption at risk in ways that generic AI tools were not designed to prevent. And unlike a typo or a formatting error, a hallucinated statistic in a client deliverable doesn’t announce itself. It reads exactly like accurate information, in exactly the same professional tone, with exactly the same confident structure.
The difference between AI that exposes your practice to this risk and AI that manages it is not which tool you use. It’s the prompt architecture behind the inputs. Expert AI prompts for consultants are built to reduce hallucination risk at the structural level — before the output is ever generated.
What AI Hallucinations Actually Are — And Why Consultants Face Elevated Risk
An AI hallucination is not a random error. It’s a specific failure mode: the model generates output that is plausible and fluent but factually incorrect, often because it is completing a pattern rather than retrieving verified information. The output reads like knowledge. It isn’t.
For consultants, three categories of hallucination surface most frequently in client-facing work. Statistical fabrication — invented figures presented as established research data. Source invention — citations to reports, studies, or organizations that don’t exist or didn’t say what the AI attributes to them. And strategic reasoning errors — logically structured arguments built on unverifiable premises that sound authoritative precisely because they’re well-organized.
⚠ Hallucinated content doesn’t look like an error. It looks like the rest of your document — which is exactly what makes it dangerous in client-facing work.
The consulting context amplifies these risks for a specific reason: clients pay premium rates for accuracy and act on deliverables in high-stakes decisions. The more polished and professional the output, the more credible hallucinated content appears — and the less likely it is to be caught before it reaches a client.
How Generic Prompts Increase Hallucination Risk
Generic prompts leave the AI with too much inferential latitude. A prompt like “write a market analysis for [industry]” or “summarize the competitive landscape for [sector]” gives the model no sourcing constraints, no factual scope boundaries, and no output format requirements that would make errors visible before delivery.
The result is what might be called “confident vagueness”: the AI produces fluent, well-structured content that sounds authoritative but draws on pattern-completion rather than verified knowledge. Competitor names, market share figures, regulatory references, and strategic benchmarks get generated the same way the rest of the text does — by predicting what should come next, not by accessing what is actually true.
The prompt patterns that most consistently correlate with hallucination risk in consulting contexts include: open-ended research requests without source constraints, broad market or competitive analysis queries without specified scope limits, and requests for specific statistics or figures without explicit instructions to flag uncertainty. All three are common in generic prompt libraries. None of them belong in a consulting workflow.
How Expert AI Prompts for Consultants Reduce This Risk
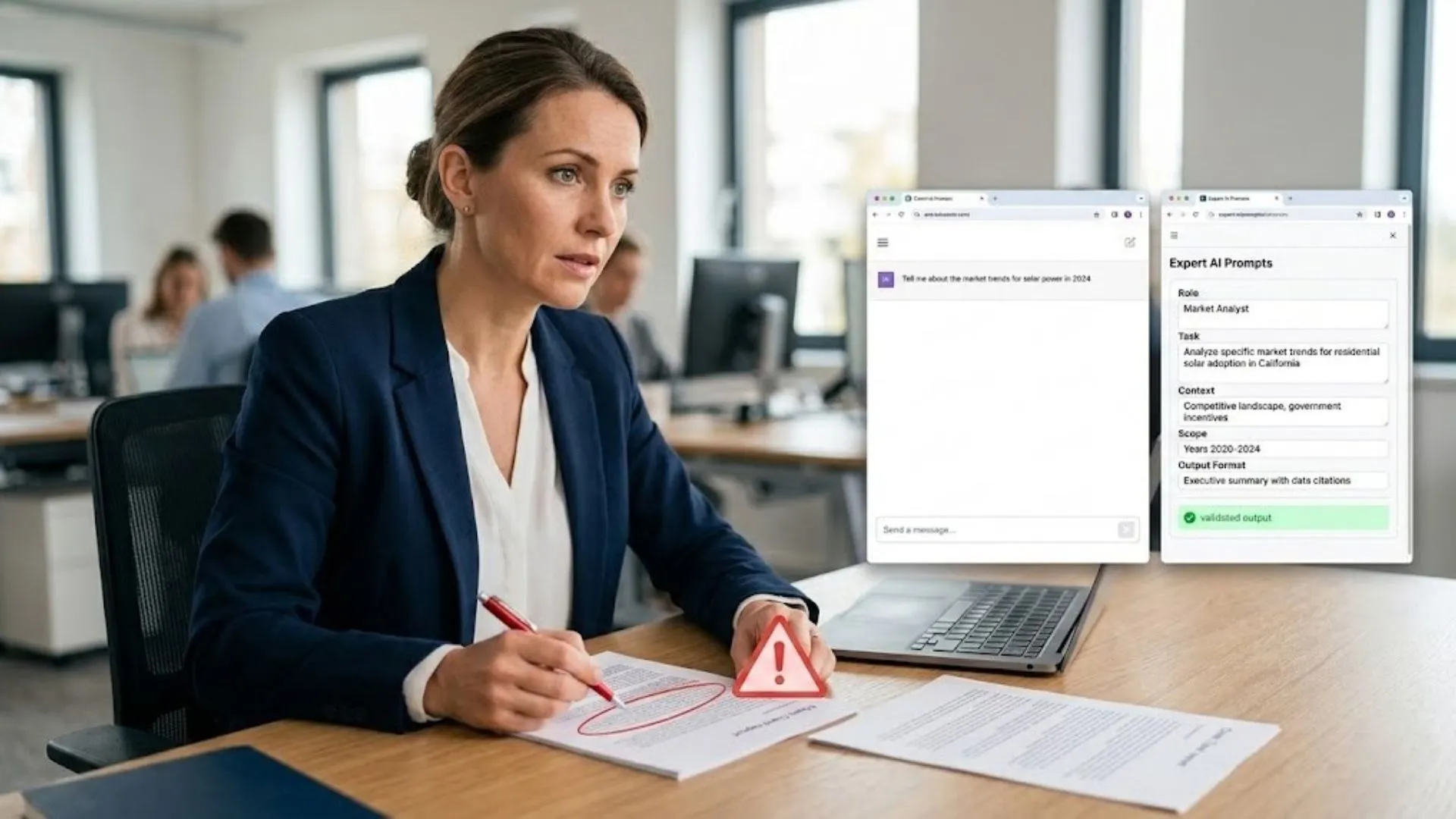
The structural solution to hallucination risk is constraint. Expert AI prompts for consultants are engineered to narrow the AI’s inferential range through a multi-layered architecture: role definition (who the AI is acting as), task specification (exactly what it is being asked to do), context provision (what background information constrains the output), scope boundaries (what the AI should and should not claim as established fact), and output format requirements (how the result should be structured).
These constraints serve two functions simultaneously. They reduce the conditions that produce hallucinations by giving the model less latitude to fill gaps with invented content. And they make hallucinations easier to detect when they do occur — because a structured, clearly formatted output with specific field requirements makes anomalies more visible before the document leaves your desk.
The sourcing parameter is particularly critical. Expert prompts include explicit instructions about how the AI should handle factual claims: flagging uncertainty, distinguishing between established data and reasoned inference, and avoiding attribution to sources it cannot verify. Generic prompts include none of this. The difference in output reliability is significant.
The Consulting Deliverables Most at Risk — and the Prompt Approach for Each
Not all consulting deliverables carry equal hallucination risk. The highest-risk formats share a common characteristic: they require specific factual claims that the AI cannot verify from general training data. Here’s how expert prompt architecture addresses each:
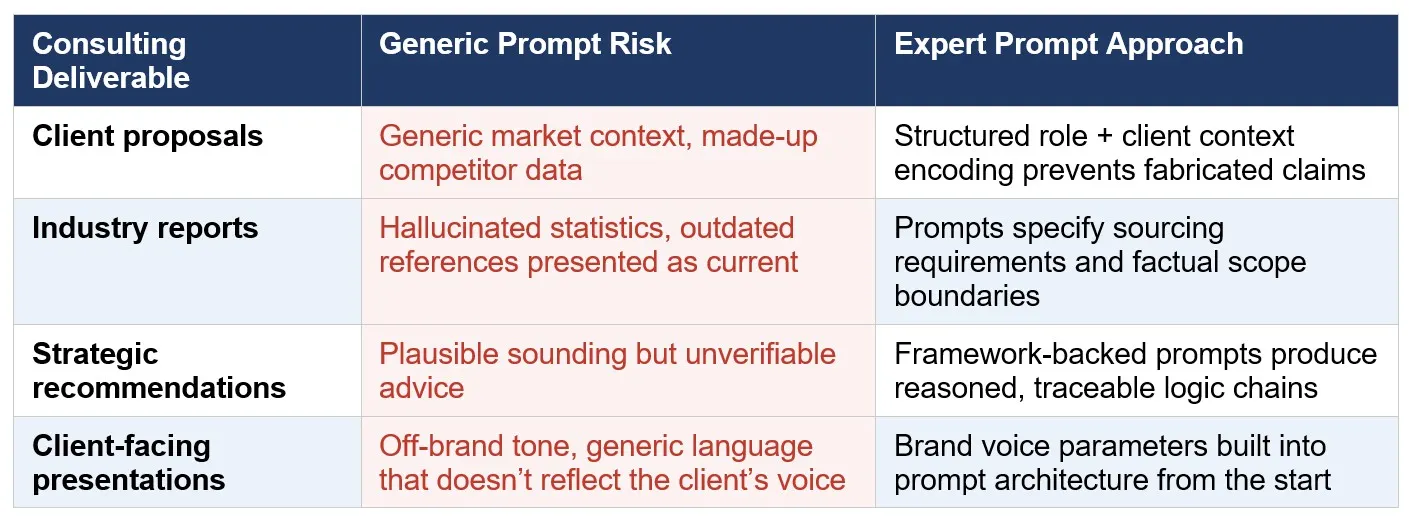
The pattern across all four categories is the same: expert prompt architecture doesn’t eliminate the need for consultant review — it makes that review faster, more targeted, and more likely to catch errors before they matter.
Credibility Is Built Over Years. Prompt Architecture Protects It.
A single hallucinated statistic in a client report doesn’t just damage the deliverable. It damages the relationship, the reputation, and potentially the retainer. For a consulting practice where trust is the entire product, the professional standard isn’t just producing outputs faster — it’s producing outputs that hold up.
Expert AI prompts for consultants are built on the premise that speed without accuracy is a liability in professional services. The prompt architecture behind each pack is designed to give you both: faster production of client-ready deliverables and structural constraints that reduce the hallucination risk that makes generic AI unsuitable for consulting contexts.
This is the standard your clients expect. It’s the standard your practice deserves.
See the full prompt pack lineup built for consulting and professional services:
https://expertaiprompts.com/prompt-packs